![]() Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
Seksenli yıllarda İngilizlerin Central Computer and Telecommunications Agency isimli departmanı, IT hizmetlerindeki sıkıntıların tespiti ve doğru yolun bulunması amacıyla ITIL olarak kısaltılan bir konseptin temellerini ortaya koymuş. Tam olarak açılımı Information Technology Infrastructure Library şeklinde. Ona kütüphane denmesinin makul bir sebebi de süreçlere ait pratikleri içeren beş kitaptan oluşması. O yıllarda temelleri atılan ITIL zaman içerisinde yeni versiyonları ile birlikte gelişmeye devam etmiş. Bugün pek çok IT firmasının(ki sadece IT ile sınırlamak doğru değil nitekim içerisinde hizmet geçen her alanda ele alınabilir) uygulamaya çalıştığı bir, bir…Şey…Immm…Bir ne?
İşte geçtiğimiz günlerde Doğuş Teknoloji tarafından düzenlenen “ITIL Farkındalık” eğitiminde bu sorunun cevabını bulmaya çalıştık. Ben, her zaman olduğu gibi heyecanla not tutmaya çalıştım. Bir günlük eğitimde yaklaşık onaltı sayfalık not çıkmıştı. Üstelik kaçırdığım bir çok kısım vardı.
Konuya belkide uzun zamandır hayatımda(hayatımızda) olan Service Now ürününden bahsederek başlasam iyi olur. Bazen çalışmayan masa telefonu için, bazen Test ortamından PreProd’a aktarılacak bir SQL Script taşıması için, bazen canlı ortam geçişindeki değişikliğe ait geri dönüşüm dokümanının eklemenmesi için, bazen ekibin üzerine düşen ve belli bir sürede çözülmesi beklenen hizmet kesintisine ait kayıda bakmak için kullanmakta olduğumuz ServiceNow ürününden bahsediyorum. Gerek önceden çalıştığım ING Bank gerek şu an çalışmakta olduğum Doğuş Teknoloji bünyesinde hali hazırda kullanmakta olduğumuz bir ürün.
Neredeyse altı yıldır karşımda olan bu ürünün, ITIL pratiklerinin şirket bünyesinde uygulanması ve hizmet kalitesinin arttırılması için kullanıldığını fark etmem ne acıdır ki bu eğitime nasip oldu. Eğitmenimiz Fırat Okay bir gün boyunca bizleri bilgilendirdi. Aslında proje yönetimi gibi bir konuyla alakalı olacağını düşündüğüm bir eğitimdi ve bu önyargı ile güne başlamıştım(Kimse duymasın sıkılacağımı düşünüyordum) Ancak Fırat hocamız cidden doyurucu bilgiler vererek tabiri caizse ITIL’ı bana sevdirdi.
ITIL’ı anlamak için şu soruyu sormamız gerekiyor; “IT hizmetlerini nasıl daha kaliteli hale getirir ve yönetiriz?”
Bir elektronik posta servisini göz önüne alalım. Bu servis temel olarak müşterilerin haberleşme ihtiycını karşılar. Bu ihtiyacın karşılanması için tasarlanan sistemin içerisinde yazılım(software) ve donanım(hardware) bir arada yer alır. Ancak detaylara inildiğinde işin içerisine güvenlik(security), ağ yönetimi(network management), firewall, anit-virus koruması, router, switch, veritabanı, mail uygulaması gibi konu başlıkları da dahil olur. Üstelik bu konular hem istemci hem de sunucu tarafını ilgilendirir niteliktedir. Görüldüğü üzere basit bir email servisi gibi görünse de, içerdiği bileşenler nedeniyle karmaşık bir sistemle karşı karşıya olduğumuzu söyleyebiliriz.
ITILcada “servis” veya “hizmet” terimi, müşteriye fayda sağlayan ve onun ihtiyacını karşılayan anlamına gelmektedir.
Bu örnekte aslolan hizmettir(Service) Müşterinin belli bir ihtiyacını karşılamak üzere tasarlanır. Hizmet bileşenleri yukarıdaki örnekte bahsettiğimiz gibi karmaşık bir sistemin parçaları olabilir. Ayrıca her bir bileşen farklı sayıda ve beceride takımların sorumluluğunda işletilebilir. İşin içerisine sorumluluk girince tahmin edeceğiniz üzere dikkat edilmesi gereken hususların sayısı da artar. ITIL , işte bu takımların hizmet faydası ekseninde birleştirilmesini amaç edinir.
![]()
Elbette hizmeti sadece IT kapsamında bir olguymuş gibi düşünmemek gerekir. Hatta ITIL’ın faydasının farkına varmak için neden otele ya da restorana gittiğimizi düşünmek gerekir. Bir restorana gittiğimizde bizi kapıda karşılayan kişiden, siparişimizle ilgilenen garsona, mutfaktaki aşçıdan kasiyere kadar herkes verilen hizmetin farkındadır. Müşteriyi(bizi) memnun etmek için herkes kendi sorumluluğunun bilincinde hareket eder ve en iyi hizmeti sunma misyonunun bir parçası olur(İyi restoranlardan bahsediyoruz tabii) Bu farkındalığın bir sonucu olarak ortaya çıkan kaliteli hizmet, sadık müşterilerin ortaya çıkmasına ve restoranın itibarının artmasına sebep olur. Ancak bu farkındalık düzeyi potansiyel Service-Provider rolünde olan her IT organizasyonu için geçerli değildir. Çünkü IT organizasyonuna dahil olanlar bazen bu hizmet olgusunun farkında olmazlar. Dolayısıyla ITIL’ın bu soruna çözüm aradığını da söyleyebiliriz.
ITIL içerisindeki terimler düşünüldüğünde bazı kavramların dikkatli kullanılması gerekir. Hizmet kalitesinden bahsederken bu hizmetin müşterilerin ihtiyacını karşılamak için var olduğunu belirttik. Ancak ITIL kütüphanesine göre müşteri(Customer) ve kullanıcı(User)şeklinde iki ayrı rol söz konusudur. Temelde hizmeti talep eden ve hatta bunun parasını veren tarafı müşteri olarak tanımlayabiliriz. Hizmet ortaya çıktıktan sonra bunu kullanan kişi ise kullanıcı rolünde değerlendirilir.
Fırat hocanın bu ayrımla ilgili verdiği güzel bir örnek de var; Henüz küçük bir çocuğun ebeveyninden bisiklet istediğini düşünelim. Bisikleti araştıran, parasını veren, satıcı ile anlaşan ebeveyn müşteri(Customer) olarak düşünülebilir. Destek tekerlekli sevimli bisikletine kavuşan o minnak çocuk ise kullanıcı(User) olarak tanımlanır.
Eğitimin bu kısımlarında ITIL içerisindeki temel kavramları incelemeye devam ettik. Az çok servisin ne anlama geldiğini, servis müşterisi ve kullanıcısının nasıl ayrıştırıldığını öğrendik. Materyaller yavaş yavaş toplanmaya devam ediyordu. İşin içerisinde servis varsa bunların kurumsal anlamda yönetimi de ITIL açısından değer kazanmakta ki bu durum Service Management olarak ifade edilmekte. Kısacası servisleri nasıl yönetiriz sorusuna cevap aradığımız bir konu olduğunu belirtebiliriz.
Servisler kuvvetle muhtemel süreçlerle(Process) ilişkili olacaktır. Sonuçta bir hizmetin devreye alınması, yönetimi, takibi ve diğer bir çok organizasyonel konu süreçlerle ilişkili. Normal şartlarda süreçleri, belli bir amaç için bir araya getirilmiş aktiviteler dizisi olarak düşünebiliriz. Kurum içindeki iş yapış biçimlerini tanımlamak gibi önemli bir rolleri vardır. Bir çağrı merkezinin talep karşılama adımlarından birisini süreç olarak değerlendirelim. Burada çağrıların nasıl geldiği, neye göre önceliklendirileceği ve çıktının ne olacağı gibi soruların cevapları sürecin aktiviteleri tarafından karşılanacaktır. Aktivite söz konusu olduğunda yine ITILcalaştırılmış bir başka kavram daha karşımıza çıkıyor; fonksiyonlar(Functions)
ITIL’ın güncel sürümünde 26 ayrı sürecin olduğundan bahsediliyor(Bunu bi araştıralım Burak)
Fonksiyonlar süreç kapsamında ilgili aktiviteyi gerçekleştirecek ekip veya araçlar olarak tanımlanmakta. Dolayısıyla kimin ya da hangi aracın, süreç kapsamındaki hangi fonksiyonu işleteceğinin bilinmesi ve yönetimi de ITIL’ın uğraştığı konular arasında yer almakta. Buradan da fonksiyonların rolleri(Roles) ve sorumluluklarının(Responsibilities) önem kazandığını söyleyebiliriz.
Service, Service Management, Customer vs User, Process, Function, Roles ve Responsibilities…Şu ana kadar ITIL dünyasında ilerleyebilmek için bilinmesi gereken temel terimlerdi. Artık asıl mevzuya girilebilir. Şaşırtıcı olmasa gerek ITIL’ın da bir servis yaşam döngüsü bulunuyor.
![]()
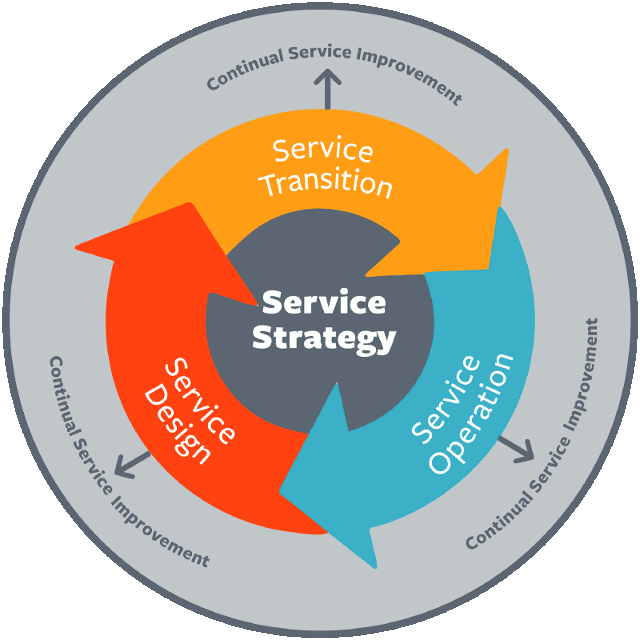
Döngüler bizim hayatımızın olmassa olmazı değil mi? ITIL’da olsa, Agile’da olsa sürekli iyileştirmeye dayanan bir iterasyon zinciri söz konusu. Yukarıdaki güzel şeklin de ifade edeceği üzere ITIL, beş temel başvuru kitabıyla tanımlanmış bir yaşam döngüsü olarak düşünülmeli. Kısaca bunların temel özellikleri üzerinde konuşarak ilerleyelim.
Service Strategy
İhtiyacın belirlendiği aşamadır ve şu sorulara cevap bulan pratikler içermektedir.
- Biz kimiz?
- Vizyonumuz nedir?
- Kime hitap ediyoruz?
- Müşterimiz kim?
- Hedeflerimize ulaşmak için izleyeceğimiz yol/yordam nedir?
- İhtiyaçları karşılamak için ne tür hizmetler sunmalıyız?
Service Design
Tasarımın yapıldığı safha olarak düşünülebilir. Strateji aşamasında alınan kararlara göre servis tasarımı oluşturulur. İhtiyaca yönelik bir tasarımın oluşturulması için gerekli doneleri sağlar.
Service Transition
Testlerin yapıldığı, test sonuçlarına göre hizmetlerin taşındığı(Deployment) aşamanın tariflendiği bölüm olarak düşünülebilir.
Service Operation
Devreye alınan hizmetin işletildiği kısmı tanımlar. Hizmetin müşteriye/kullanıcıya sunulduğu ve aslında ITIL’ın en önemli aşamasıdır(Yani en azından eğitimde en çok üzerinde durduğumuz aşamaydı)
Continual Service Improvement
Aşağıdaki soruların cevaplandığı iyileştirme safhasıdır.
- Neler iyi gidiyor?
- Neler kötü gidiyor?
- Eksikler neler?
- Neleri iyileştirmek lazım?
Retrospective toplantıları geldi aklınıza değil mi? :)
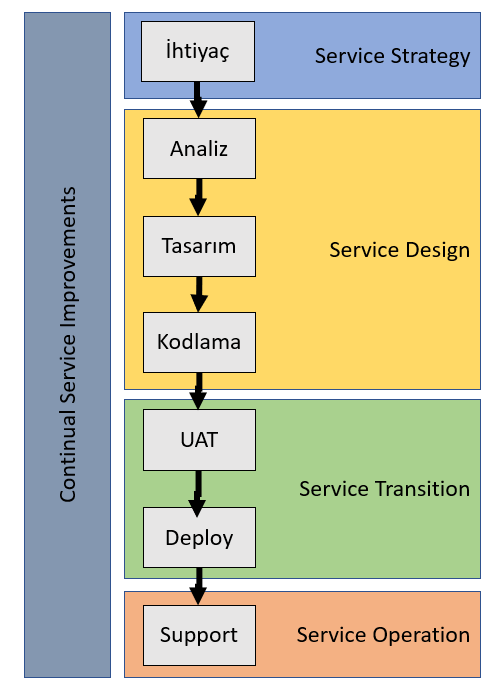
Yaşam döngüsünde yer alan Design, Transition ve Operation kısımları sürekli bir iterasyon halinde işlemektedir. Aslında tipik bir yazılım geliştirme sürecini ele aldığımızda ITIL’ın bu süreç üzerinde denk düştüğü belli başlı yerler olduğunu da söyleyebiliriz. Aşağıdaki şekle bir bakalım.
![]()
İhtiyaçları belirledikten sonra analizini yapıp bir tasarımın ortaya konması ve buna göre kodlama yapılması söz konusudur. Bunu kullanıcı kabul testleri(User Acceptance Test) ve sonuçlarına göre dağıtım(Deployment) işlemleri takip ediyor. Dağıtılan ürüne daha sonradan destek verilir.
Evet, biraz Waterfall’a benzer bir yapı gibi görünüyor. Benim kafamda da benzer soru eğitim sırasında oluşmadı değil. Lakin ITIL’ın yaşam döngüsünün de iterasyonlar üzerine dayalı olduğunu görmekteyiz. Bu açıdan bakıdığında Agile yürüdüğümüz yapılar için de iz düşümlerin olduğunu söylemek sanıyorum ki mümkün. Nitekim bir Product Backlog Item’ı sprint’e dahil ettiğimizde onun kısa bir analizi, task’lar halinde parçalanması, task’lara ait kodlamanın yapılması, DevOps söz konusu ise test iterasyonlarının çalıştırılması ve belki de Sprint için bir UAT gerçekleştirilmesi, sprint sonuna gelindiğinde müşteri için değer yaratan increment’lerin dağıtımı ve operasyonun takibi… Pek tabii tüm bu operasyon sürecinin gözden geçirilmesi, gerekli iyileştirmelerin yapılması ve yeniden ihtiyaçların belirlenip aynı akışın devam ettirilmesi…İşte kalıba uydu:)
Tabii bana göre ITIL‘ın uygulanabilir nitelikte olduğu projeler olmalı. Bir başka deyişle IT açısından ne tür hizmetlerin ITIL çerçevesinde değerlendirilmesi gerektiğinin bir takım kriterleri olmalı. Bakalım notlarımızın sonunda bu soruya cevap bulabilecek miyiz?
Eğitimin bundan sonraki kısımlarında yaşam döngüsünde yer alan bazı maddelerin biraz daha detayına girmeye çalıştık. İlk olarak Service Operation sürecini ele aldık.
Service Operation Process(Biraz daha detay)
Bu safhada Event Management, Incident Management, Request Fullfilment, Problem Management ve Access Management gibi çeşitli alt yönetim süreçleri tanımlanıyor(ITIL versiyonlarına göre farklılıklar olabilir)
Olay yönetimi sürecinde durum değişikliklerinin izlenmesi ile ilgili işlemlere yer verilmektedir. Örneğin bir kullanıcının sisteme Login olması, servisin yeniden başlatılması veya durması gibi haller bu bağlamda düşünülebilir.
Request Fullfilment sürecinde, kullanıcıdan gelen basit ve çabuk gerçeklenebilir isteklere yer verilir. Paralo sıfırlama, biten yazıcı kartuşunun değiştirilmesi, yer değişikliği nedeniyle PC IP adresi taşınması, ortak alandaki bir klasöre erişim yetkisi gibi istekleri örnek gösterebiliriz.
Erişim yönetimi(Access Management) adındanda anlaşılacağı üzere yetkilendirme ile alakalı bir süreçtir. Bir kullanıcının ilgili domain’e eklenmesi, uzak sunucuya erişim yetkisi alınması örnek olarak verilebilir.
Eğitim sırasında üzerinde daha çok durduğumuz ve kısımlar Incident Management ve Problem Management süreçleriydi. Incident ve Problem birbirleriyle çok sık karıştırılabilen kavramlar olduğu için eğitimin bu safhasını biraz daha derinleştirdik.
Devreye alınmış bir hizmette yaşanan plan dışı bir kesinti genel olarak Incident şeklinde adlandırılmakta. Tahmin edileceği üzere bu tip kesintilerin belirlenen veya müşteri ile anlaşılan süreler içerisinde çözümlenmesi bekleniyor/gerekiyor. Aksi durumda hizmet kesintisinin ürünün veya hizmetin itibari üzerinde olumsuz etkileri olması kuvvetle muhtemel.
Geliştirici olarak bizleri en çok ürküten postaların başında Incident kayıtlarına ait bildirimler gelir dersek yeridir. Bir Incident’ın büyüklüğü ve aciliyetine göre SLA(Service Level Aggrement) içinde tanımlanmış sürelerde çözülmesine uğraşırız. Hatta tanımlanan zamanın %25ini, %50sini ya da %75ini tükettiğimizde daha ciddi şekilde uyarılırız. Hele ki Incident çözüme kavuşmazsa…
Bu durum sorunun süreçteki bir üst pozisyona eskale edilmesi ile sonuçlanabilir. Burada bahsi geçen SLA esasında müşteri ile el sıkışılan bir konudur. SLA’in bir amacı, üzerinde anlaşılan seviyelerde hizmet sunulmasını garanti etmektir. Service Design aşamasında tanımlanan SLA’lerin kardeşleri de var. İlerleyen kısımlarda onlar da karşımıza çıkacak.
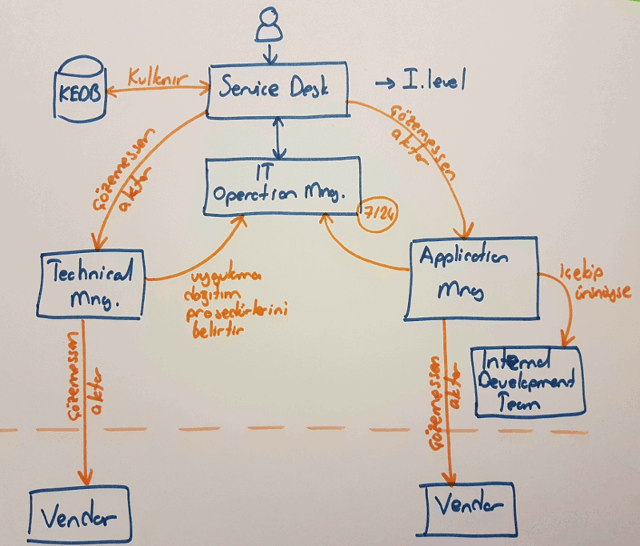
Belki garip gelecek ama Incident hallerinde günü kurtaracak çözüm neyse uygulanması gerekir(Söz gelimi printer’dan evrak çıktısı alınamıyorsa bir şekilde geçici çözüm uygulanıp sorun giderilmelidir)İşte bu sebepten problem yönetimi isimli ayrı bir süreç daha vardır. Çok sık tekrar eden, etkisi büyük olan veya üst yönetime kadar eskale olduğu için önem arz eden bazı sorunlar problem olarak tanımlanır ve kök nedenleri araştırılır. Bu kök nedenlere bakılaraktan Incident’ların tekrardan oluşmasını önlemek amacıyla kalıcı çözümler uygulanır. Problem yönetimi sürecinde esas amaç kök nedenlerin bulunup kalıcı çözümlerin uygulanmasıdır. Problemler genellikle Workaround, Known Error şeklinde değerlendirilirler. Hatta bilinen hatalar KEDB(Known Error Database) adı verilen veritabanında saklanırlar.
Incedent olarak gelen bir bulgu mutlaka çözülmek durumundadır. Çünkü sistemde kesinti söz konusudur. Ancak Request Fullfilment aşamasında bir zorunluluk yoktur. Nitekim istekler onaya tabidir.
Incident ve Problem yönetimi, Olay izleme ile birleştirildiğinde hizmet kesintilerinin ve sorunlarının çeşitli seviyelerde karşılanması da mümkün hale gelir. Olay izlemedeki bilgilerden yararlanılarak henüz meydana gelmeyen bir kesintinin önceden tespit edilmesi, buna istinaden bir problem kaydının oluşturulup, kök neden tespiti ile kalıcı çözüm uygulanabilmesi sağlanabilir (Bu durum çoğunlukla Proactive Problem Management olarak adlandırılmaktadır) Ancak bu her zaman mümkün değildir. Çünkü işin içerisinde değişim yönetimi(Change Management) denilen ve uygulanacak çözümün çeşidi, büyüklüğü, kritikliğine göre devreye girecek bir onay mekanizması da olabilir.
Servis operasyon sürecinde dört temel fonksiyon(veya ekip diyelim) bulunur. Aşağıdaki şekilde aralarındaki ilişki özetlenmektedir.
![]()
Çoğumuz farkındayızdır. Firmada 7x24 etkin görev alan bir operasyon ekibi vardır. Bazı sorunlara otomatik olarak müdahale ederler(Aslında bazı kesintiler önceden tespit edilip robotlaştırılmış süreçler işletilerek sorunlar hissettirilmeden bertaraf da edilebilir) Diğer yandan müşteriden gelen bir kesinti ihbarında bunu ön cephede karşılayan hizmet destek ekibi vardır. Çoğunlukla birinci seviye olarak düşünebileceğimiz bu ekip ilgili sorunu çözmeye çalışır. Bunu yaparken daha önceden kayıt altına alınmış bilinen problemlere ait ipuçlarından da yararlanabilir. Tabii defalarca karşılaşılmış ve birinci seviye tarafından birçok kez çözülmüş bir bulgunun kalıcı olması da iyi değildir. Bunu problem olarak değerlendirip kök sebebini araştırmak ve kalıcı çözüm uygulamak gerekir. Yine de hizmet masası sorunu çözemezse tipine göre bu sorunu teknik veya uygulama yönetim ekiplerine aktarabilir (Çözemessen aktar modeli)
Teknik ve uygulama yönetimi ekiplerinin aslında IT Operasyon ekibiyle sıkı ilişkisi vardır. Genellikle hizmetin dağıtımı ile ilgili prosedürleri operasyon ekibine de aktarırlar ki bir sorun oluşması halinde 7x24 müdahale edilebilsin. Teknik yönetim kendisine gelen bir bulguyu çözemezse ve bu bulgu üçüncü parti bir servis sağlayıcıya aitse(Vendor) ona aktarır(Ticket açıldı deriz ya bazen) Benzer durum uygulama yönetimi içinde geçerlidir. Lakin burada iki farklı durum olabilir. Bazı uygulamalar iç ekiplerce geliştirilmiştir. Dolayısıyla ilgili bulgu uygulama sahibi ekibe yönlendirilir. Ancak uygulama yine dış firma kökenli ise sorun için ilgili servis sağlayıcıya bir Ticket açılır.
Bulguları özellikle üçüncü parti fimaya indirgemeye gerek duymayacak şekilde hizmet geliştirmek bence önemlidir. Bu ancak işin en başından itibaren sistem dinamiklerini sürekli olarak test etmekten, test etmekten, test etmekten ve yine test etmekten geçmektedir. TDD gibi yaklaşımlar her ne kadar geliştirme sürelerini uzatsa da, uzun vadede sağlayacağı garantörlük dikkate alınmalıdır.
Service Transiciton Process(Biraz daha detaylı)
Hizmeti devreye alma süreci olarak tanımlanmıştır. Devreye alınacak, emekli edilecek veya değişikliğe uğrayacak hizmetler ile ilgili her türlü dağıtım işleminin tariflendiği süreçtir. Change Management, Configuration Management, Release and Deployment Management, Transision Planning and Support, Change Evoluation, Knowledge Management gibi alt süreçleri barındırır.
Dikkat edileceği üzere değişim ve konfigurasyon yönetimi de bu süreçler içerisinde yer almaktadır. En önemli süreçlerden birisi değişim yönetimidir. IT süreçlerine etkisi olabilecek her türlü durum değişikliği Change Management’ın konusudur. Çalışan bir sistem üzerinde değişiklik yapmak(yeni özellik eklenmesi, özellik çıkartılması vb) her zaman için kritik ve riskli bir işlemdir. Bu nedenle değişikliğin sistem üzerinde minimum kesintiye uğrayacak şekilde yapılmasının garanti edilmesi gerekir.
Yine de sevgili Murphy’yi unutmamak lazım. Bu sebeptendir ki, değişim süreçlerinde mutlaka geri alma planları (Remediation Plan) yapılır, yapılmalıdır.
ING Bank bünyesinde çalıştığım dönemlerde taşıma yapılırken mutlaka girmemiz gereken bilgilerden birisi de geri alma planıyla ilgili olandı. Üretim ortamına bir SPmi taşınacak? Taşındıktan sonra sorun olursa sistemin durumunu tekrar eski konumuna nasıl döndüreceğiz, tariflenirdi. Bu tarifleme veritabanı operasyon ekibi tarafında önem arz eden bir konuydu.
Pek tabii günümüz modern DevOps destekli süreçlerinde olası sorunların taşıma sonrası otomatik olarak hissedilip geri alma ile ilgili programlanmış betiklerin anında yürütülmesi gibi senaryolarda mümkün. Lakin bunların yine de dokümante edilmesi şart. Çünkü sizi/bizi çeşitli regülasyonlar nedeniyle denetlemek zorunda olanlar var(Auditçilerin kulağı çınlasın)
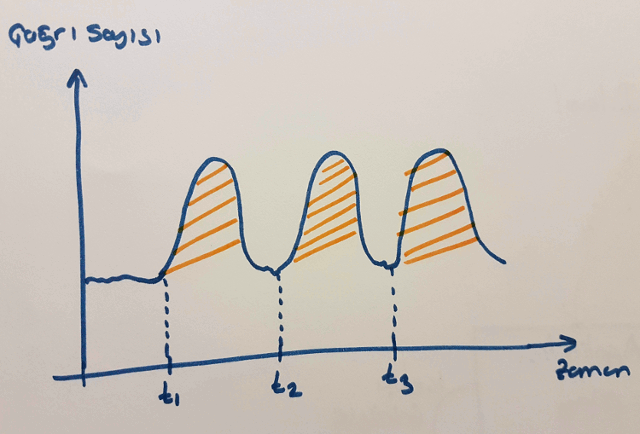
Değişim yönetiminin önemini vurgulamak için Amerikada yapılan bir araştırmayı göz önüne alabiliriz. Araştırmaya göre firmalara gelen çağrıların belirli dönemlerde tavan yaptığı fark edilmiş. Tahmin edeceğiniz üzere çağrı sayılarının anormal seviyede yükseldiği zamanlar değişiklik sonrasına denk gelen anlar. Hatta bir senelik zaman periyodundaki istatistiki verilere bakıldığında, yükselen çağrı zamanlarındaki bulguların neredeyse %90a yakınının yeni değişikliklerle alakalı olduğu saptanmış.
![]()
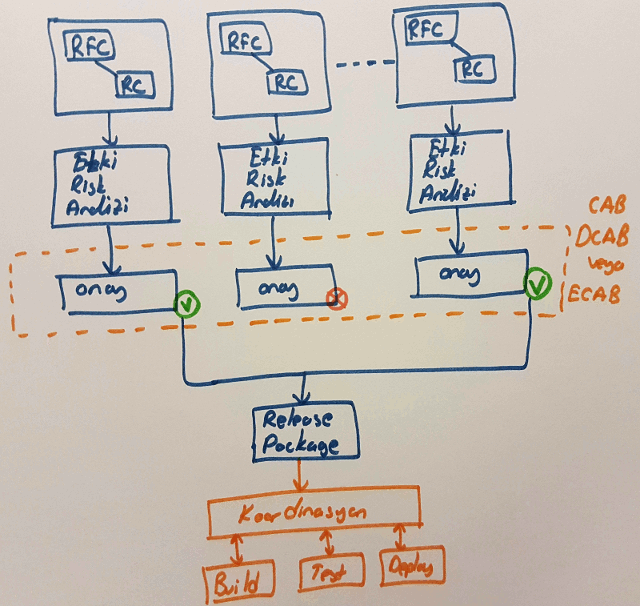
Dolayısıyla yapılacak değişikliklerin riskinin ve etki analizinin de iyi yapılmış olması beklenmekte. Change Management süreci bunu da esas alır. Yeri gelmişken değişiklik adımlarına bakmakta yarar var aslında.
Bütün değişiklikler kayıt altına alınmalıdır. Bir değişim süreci çoğunlukla RFC(Request for Change) adı verilen istekle başlatılır. Söz konusu talep, sonrasında bir değişim kaydı(Change Record) haline gelir. Değişiklikler genelde üç türlüdür. Standart olanlar, acil yapılması gerekenler ve normal şartlara uyanlar. Önceden onaylanmış ve düşük riskli rutin değişiklikler, standart olarak adlandırılırlar. Ancak üretim ortamına alınan hizmette yaşanan ciddi problemler, yasal regülasyonlar nedeniyle uygulanması gereken kurallar veya güvenlik açıklarının oluştuğu durumlar acil değişim(Emergency Change) statüsüne girer. Standart ve acil değişime uymayan haller normal değişim olarak adlandırılır ve minor ya da major tipli olarak iki şekilde kategorilendirilir.
“As soon as possible” tipinden değişimlerin “Mission Impossible” durumuna düşmesini engellemek için planlamanın iyi yapılması önemlidir.
Değişim kaydının oluşturulmasından sonraki aşama etki ve risk analizinin yapılmasıdır. Buna görede bir onay mekanizması çalıştırılır. Pek çoğumuzun yakınen bildiği şu meşhur CAB(Change Advisory Board) toplantıları yapılır. Hatta acil durumlar için ECAB(Emergency Change Advisory Board) toplantısı gerçekleştirilir. ECAB’in yapılma olasılığı düşük ve onay çıkması da çok kolay değildir. Yönetim çok aksi bir durum olmadığı sürece ritüel değişim sürecinin dışına çıkılmasını istemez. Hoş bunu geliştirme takımı da istemez. Nitekim acil değişim kaydı gerektiren durumların oluşmasına neden olan geliştirici hataları üst tarafta pek de iyi algılanmaz.
Değişim, konfigurasyon yönetimi(Configuration Management) ile de yakın ilişki içerisindedir. Herhangibir özelliğin hizmetleştirildiği süreçleri düşünün. Ortamlar için gerekli bir çok konfigurasyon ayarı bulunuyor. Sunucu adları, veritabanı bağlantıları, sertifikalar vb…Ama olaya sadece yazılım açısından bakmamak lazım. Fiziki sunucular, dokümanlar, IT kadrosu, lisanslamalar ve benzerleri de aslında birer konfigurasyon öğesi(Configuration Item) Keza bunlar arasındaki bağlantılar da değişim sürecinde önemli rol oynamakta. İlişkiler, etki analizi ve kök nedenlerin bulunmasına da yardımcı olan Configuration Management System(CMS) isimli sistem üzerinde tutulurlar.
Çoğunlukla bir sürüm(Release)çıkılacağı zaman birden fazla değişim kaydı sürece dahil olur. Bu durumda onay alanların bir paket haline getirilerek taşınması söz konusudur. Burada paketlerin build, test ve deploy aşamalarının da koordinasyonu gerekir ve bu işlemler sırasında konfigurasyon öğelerinin de sorunsuz işliyor olması önemlidir.
![]()
Release demişken; Hocamızın verdiği bilgiye göre İngiliz Barclay bankası senede bir sürüm(Release) çıkarmış. Eh onların bankacılık süreçleri veya devlet regülasyonları bizimki gibi olmadığı için bu son derece normal diyebiliriz.
Lakin ING Bank bünyesindeki dönüşüm projesi kapsamında haftada bir sürüm çıkılan dönemlere indiğimizi hatırlıyorum. Preprod ortamına kadar normal olarak ilerleyen hizmetlerin onaya istinaden bir RFC numarası ile canlı ortama alınması söz konusuydu.
Hatta kanlı bıçaklı CAB toplantıları yapıldığını hatırlıyorum. Ufak bir belgesi eksik olan değişim kaydı onaylanmaz ve o canlı ortam geçişini kaçırabilirdi.
Service Design Process (Biraz daha detay)
Tasarımın tariflendiği bu aşamada iş birimi ve operasyonun gereksinimleri işin içerisine katılarak ilerlenilir. Edindiğim bilgiye göre sekiz süreç içeriyor ancak en önemli ikisi Service Catalogue Management ve Service Level Management.
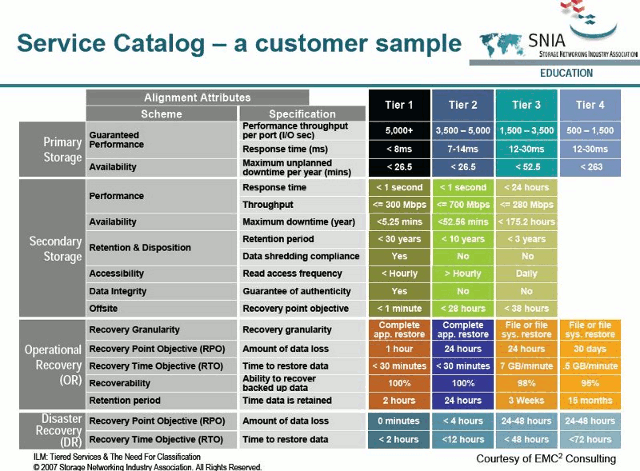
Service Catalogue daha çok ne sunduğumuzun ya da ne sattığımızın tarifini içeriyor. Eski olsa da şu grafiği göz önüne alabiliriz.
![]()
Bu örnekte çeşitli seviyelerdeki müşteriler için verilen depolama ve kurtarma hizmetlerine ait bilgiler yer alıyor. Bunu bir servis kataloğu olarak değerlendirmek mümkün. Hizmetlere ait kısa tanımlamalar dışında dikkat çekecek detaylara da yer verilmekte.
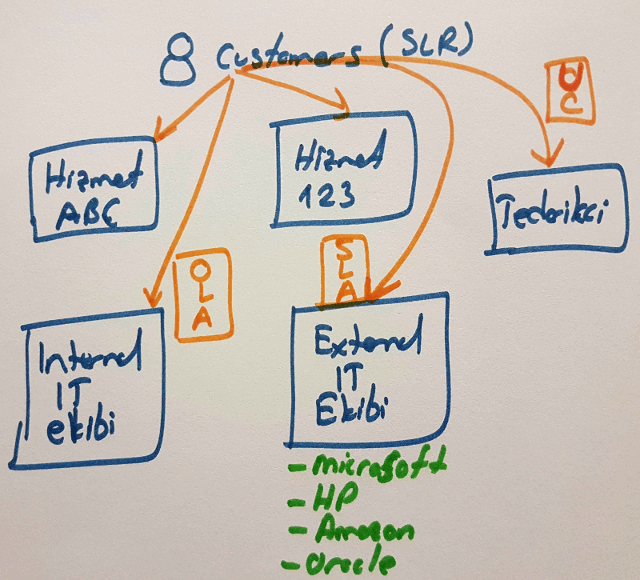
Service Level Management’ta ise bizim daha çok aşina olduğumuz bazı kavramlar var. Bunların başında Service Level Aggrement geliyor. Ancak OLA(Operational Level Aggrement) ve UC(Underpinning Contract)şeklinde iki sözleşme daha yer almakta. SLM’in temel amacı müşteri ile dahili(Internal) ve harici(External) ekipler arasında bir orta yol bulmak. Buna göre antlaşmalar yapılıyor. Antlaşmalarda belirlenen kurallar çerçevesinde de bir servis tasarımına gidiliyor.
![]()
Müşteri çok doğal olarak almak istediği hizmetlerle ilgili olarak bazı gereksinimlerini sunar(Service Level Requirements) Bu zaman zaman fonksiyonel olmayan dilekler olarak da anılır. Bu bildirgede bir hizmetin ne zaman, hangi periyotlarda çalışması istendiği, hizmette kesinti olduğunda da müdahala sürelerinin ne olacağı ve güvenlik kriterleri gibi konulara açıklık getirilir.
Buna göre müşteri ile iç ekipler arasında operasyonel antlaşma yapılır(OLA) Microsoft, HP, Amazon, Oracle ya da bizim çalışmakta olduğumuz SahaBT gibi firmalarla da SLAler imzalanır. Aslında tarafların durduğu konuma göre antlaşma bir taraf için SLA iken diğer taraf için OLA anlamına gelebilir ya da tam tersi(Bu kısma biraz daha çalışmam lazım)
ITIL, müşteriler ile ilgili SLA, UC ve OLA sözleşmelerinin işin başında yapılması gerektiğini önerir.
Tedarikçi firmalar ile yapılan Underpinning Contract ile Service Level Aggrement sözleşmesi birbirlerine oldukça benzer formattadır. Genellikle UCler çok daha ağır şartlar içerir.
SLA sözleşmesi firmanın kendi iş birimi ile geliştirme ekibi arasında da yapılmış olabilir. Bu durumda iş biriminin talep ettiği hizmetler ile ilgili aksamalarda devreye bu sözleşemelerde belirtilen reaksiyon süreleri girer. Taahüt edilen süreler içerisinde sorunun çözülmesi kaydın atandığı kişi açısından değerlidir(KPI diyeyim siz gerisini anlayın)
Service Strategy ve Continual Service Improvment Hakkında Kısa Kısa
Eğitimin sonları yaklaştıkça bendeki yorgunlukta artmaya başladı. Hocamızın güzel anlatımını pür dikkat dinlemeye çalışırken bir yandan da notlar alıyordum. Ancak her güne sabah 05:50de başlayınca ikindi vakitlerinden sonra enerji az da olsa düşüyor. Yinede servis stratejisi ve iyileştirme noktasında bir kaç kısa not almayı başardım.
Müşteriye ne sağlayacağımızı bilmek için onu anlamamız gerekir. Bu, strateji sürecinde ele alınan bir olgudur. Business Relationship Management, Service Portfolio Management, Financal Management for IT Services, Strategy Management for IT Services ve Demand Management gibi süreçleri içerir. İsimlerinden anlayacağınız üzere müşteriye sunulacak bir hizmet için organizasyonun finansal bacağından portföyündeki bileşenlerine, arz talep dengesindeki taleplerden IT stratejilerine kadar bir çok önemli kalem hesaba katılır.
Cep telefonu operatörlerinin maç günlerinde, maç sahasındaki baz istasyonlarının yetersizliği üzerine bir strateji belirleyip ilgili günlerde ilgili alanlara mobil baz istasyonları çıkartması Demand Management için güzel bir örnektir. Arzın arttığı bu vakada talepleri sorunsuz karşılayabilmek için örneğin bir aylık zaman dilimindeki maçların belirlenip mobil istasyonların çıkışını planlamak bir strateji hamlesidir.
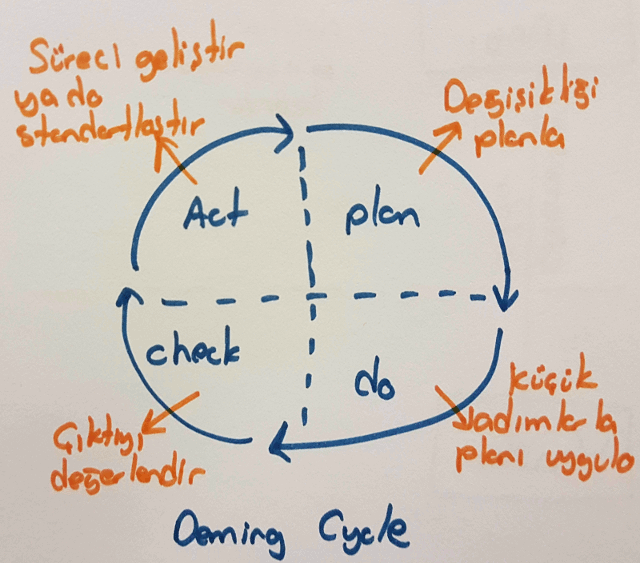
Continual Service Improvment diğer ITIL süreçlerini çevreleyen ve dolayısıyla onları gözlemleyip çıktılarını değerlendirerek sürekli iyileştirmenin ele alındığı bir safhadır. Burada adım adım, sakince ilerlenilmesi öğütlenir. Önemli olan bir husus ise ölçümlemektir. İyileştirme yapabilmek için elde metrik değerlerin olması gerekir. Bunları beslemek için de ölçme mekanizmalarının oluşturulması. CSI esasında planlama(plan), yürütme(do), kontrol etme(check) ve aksiyon alma(act) adımlarından oluşan bir döngüyü temel alır(Deming kalite çemberi)
![]()
Sonuç
Yönetemediğimiz sistemi kontrol edemeyiz. ITIL, kaliteli hizmet verebilmek, bu hizmetleri yönetebilmek, ölçümleme yapıp iyileştirebilmek için beş farklı disiplini sunmaktadır. Uygulanması bazen çok kolay görünmese de, büyük çaplı kurumsal projelerde ve özellikle müşteriye sunulan hizmetlerin yüksek itibara sahip olduğu durumlarda ITIL gibi endüstüriyel olarak standartlaşmış desenleri tatbik etmeye çalışmak uzun vadede mutlaka yararlıdır.
Aldığım bu eğitim sonrası Service Now ürününe ve iş yapış şeklimize olan bakışım daha da değişmiş oldu. Hizmeti sahiplenmenin önemli bir unsur olduğunu bir kere daha fark ettim. Elbette ITIL’ı bir şirkete kurgulayacak derecede bilgiye sahip olmamız gerek ve şart değil. Ancak içinde ServiceNow ve benzeri ürünlerin koştuğu, SLA zaman aşımı maillerinin geldiği ve CAB toplantılarının yapıldığı firmalarda bunların neden var olduğunun farkına varılması açısından yazıldığı kadarını bilmek önemli.
Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,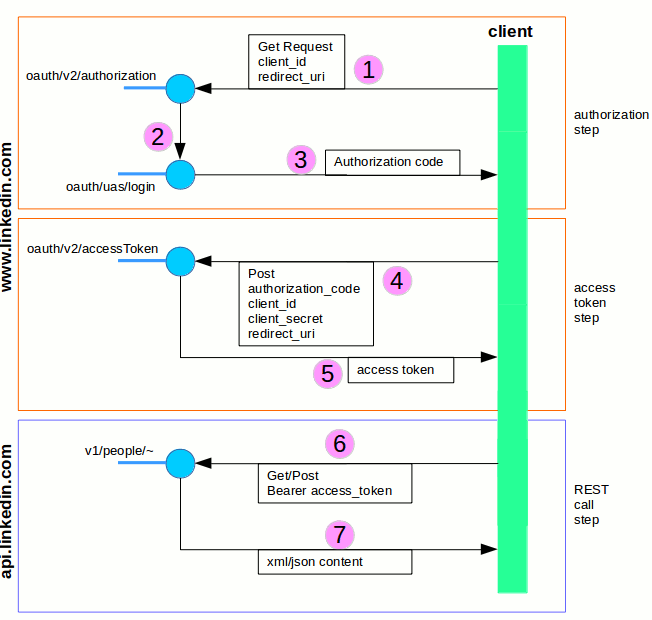


 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,


 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
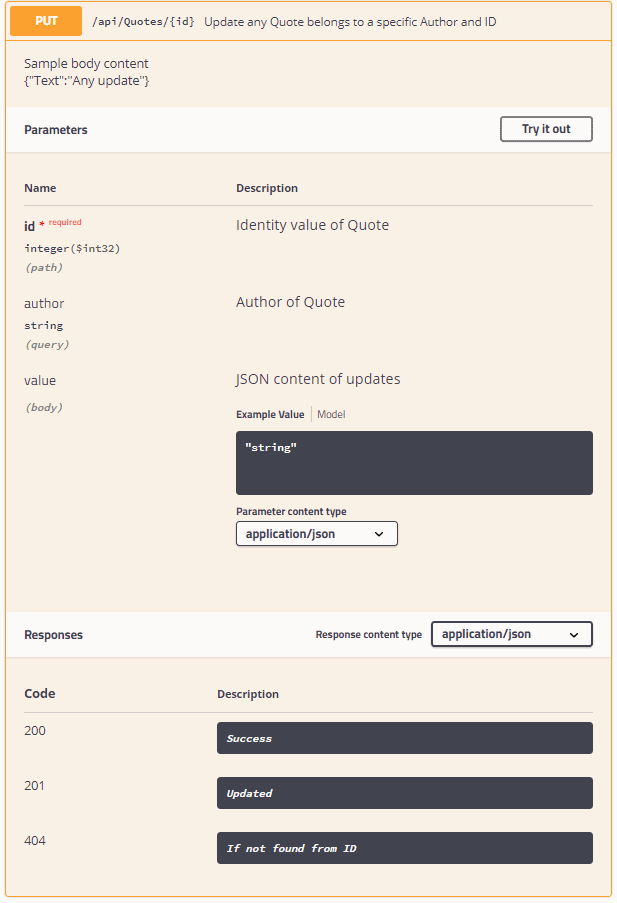
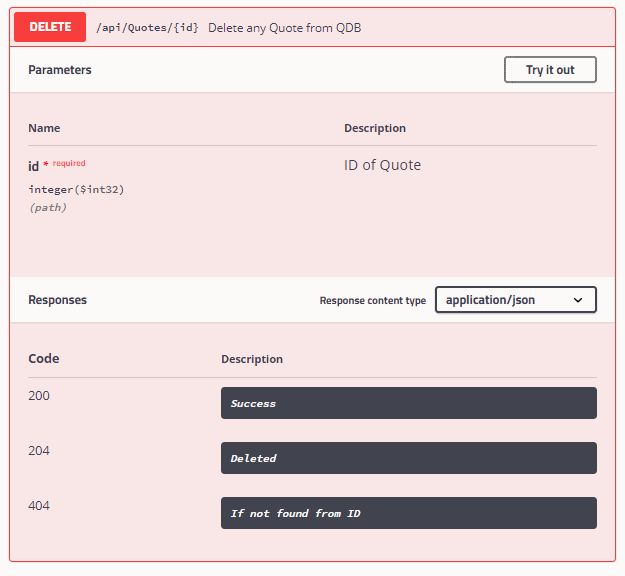
 Merhaba Burak,
Merhaba Burak,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,





 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,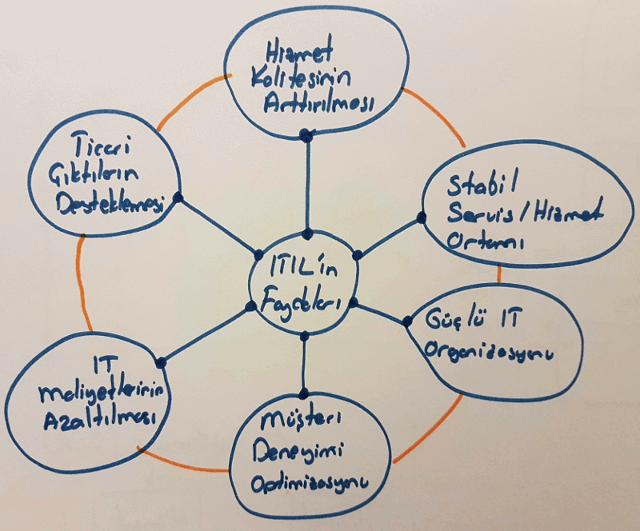
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,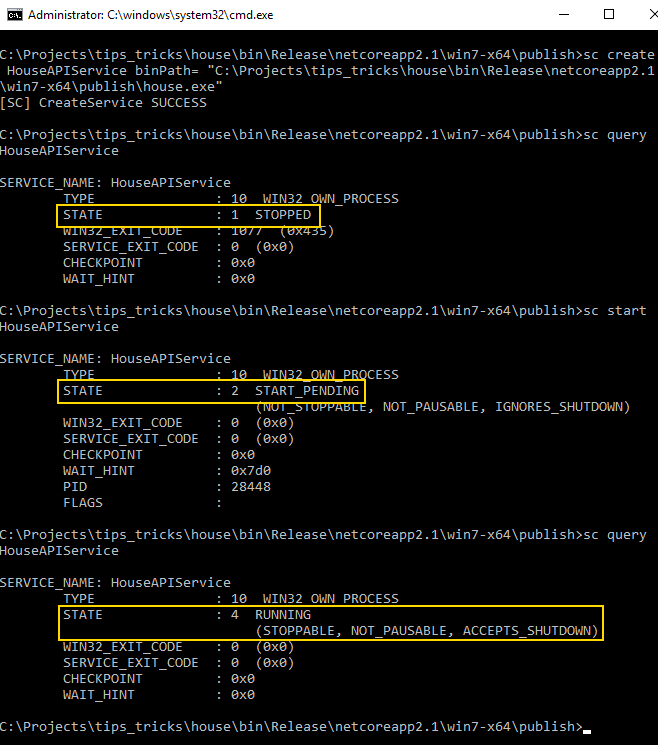
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
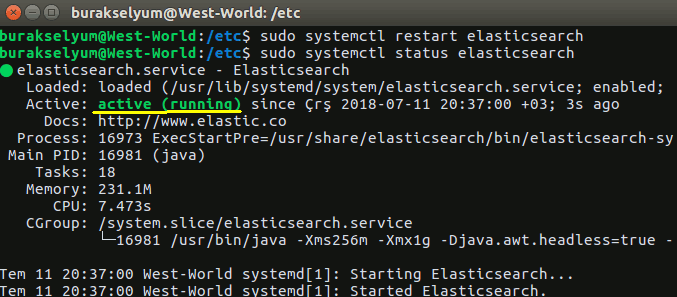

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,

 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,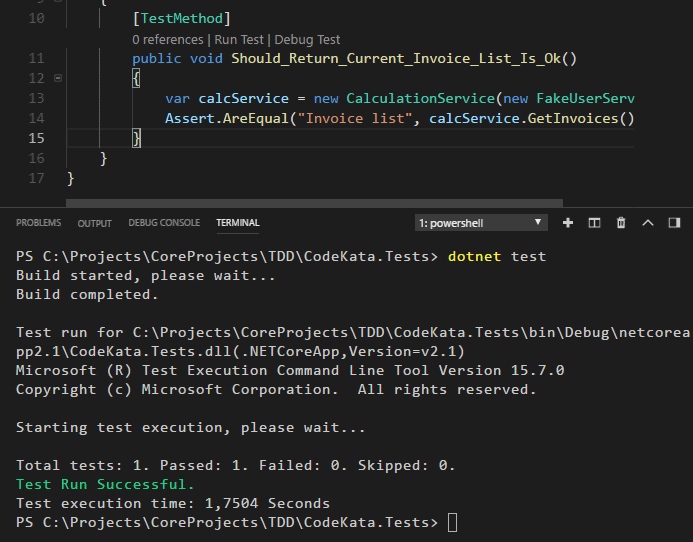
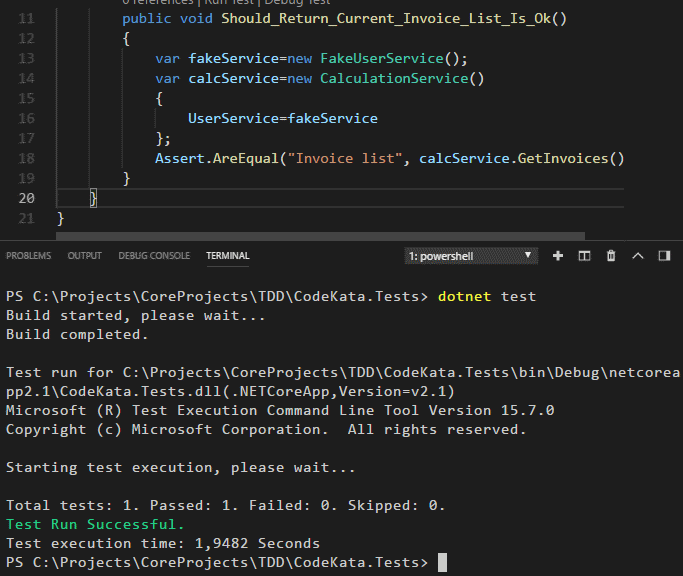
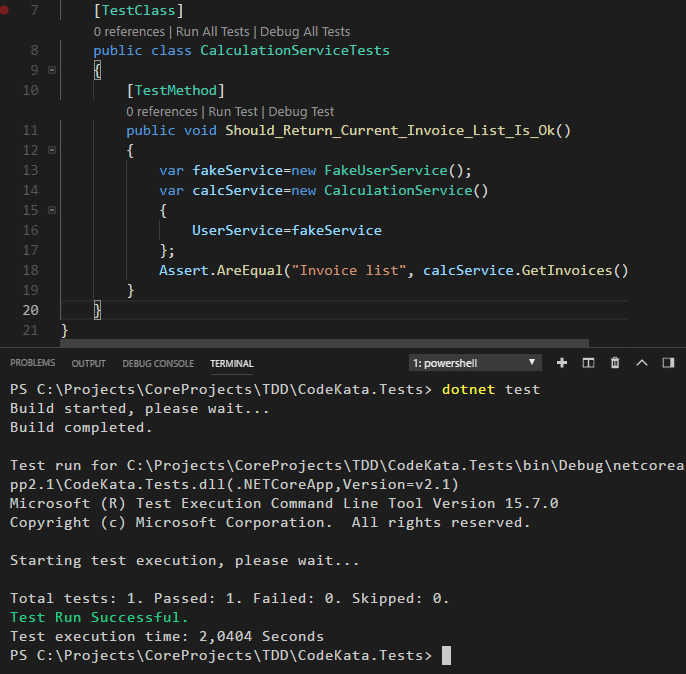
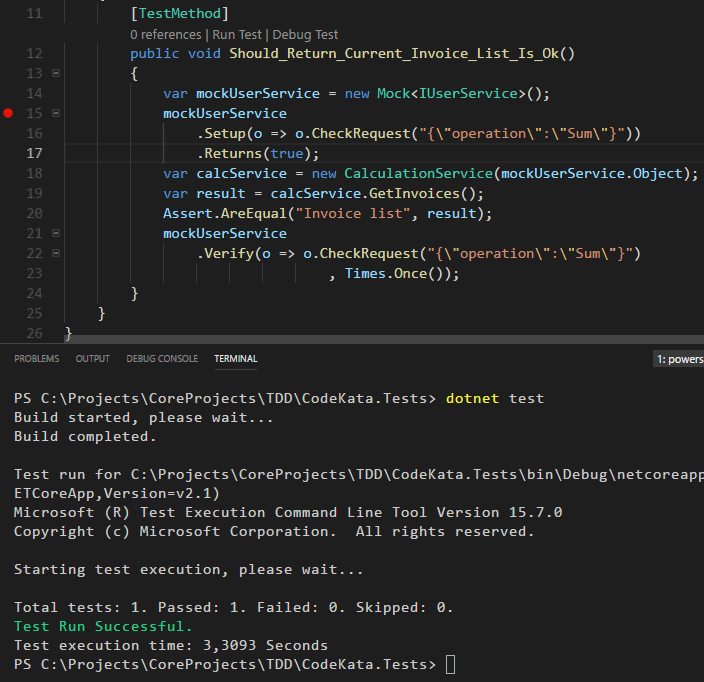
 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,




 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,






 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
